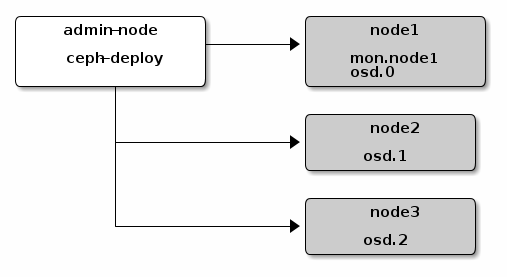
In Part 1, the infrastructure required for the initial Ceph deployment was set up on GCE. We now move on to setting up Ceph with 1 Monitor and 3 OSDs according to the quick start guide here.
SSH into the admin node as ceph-admin and create a directory from which to execute ceph-deploy.
> mkdir my-cluster
> cd my-cluster
Create a new cluster by specifying the name of the node which will run the first monitor:
> ceph-deploy new node1
Recall from Part 1 that the first nodes was named node1. A number of files will be created as a result of this command:
> ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
Next, install Ceph packages in the nodes:
> ceph-deploy install node1 node2 node3
Deploy the initial Monitor and gather they keys:
> ceph-deploy mon create-initial
At this point, the directory will have the following keys. Note that this is less than keys indicated in the quick start guide; the mgr and rbd keyrings are not present.
> ll
total 156
drwxrwxr-x 2 ceph-admin ceph-admin 4096 Aug 17 22:18 ./
drwxr-xr-x 5 ceph-admin ceph-admin 4096 Aug 17 22:18 ../
-rw------- 1 ceph-admin ceph-admin 113 Aug 17 22:18 ceph.bootstrap-mds.keyring
-rw------- 1 ceph-admin ceph-admin 113 Aug 17 22:18 ceph.bootstrap-osd.keyring
-rw------- 1 ceph-admin ceph-admin 113 Aug 17 22:18 ceph.bootstrap-rgw.keyring
-rw------- 1 ceph-admin ceph-admin 129 Aug 17 22:18 ceph.client.admin.keyring
-rw-rw-r-- 1 ceph-admin ceph-admin 198 Aug 17 22:12 ceph.conf
-rw-rw-r-- 1 ceph-admin ceph-admin 125659 Aug 17 22:18 ceph-deploy-ceph.log
-rw------- 1 ceph-admin ceph-admin 73 Aug 17 22:12 ceph.mon.keyring
Copy the config and keys to your ceph nodes:
> ceph-deploy admin node1 node2 node3
Then finally add the OSDs and specify the disk to use for storage:
> ceph-deploy osd create node1:sdb node2:sdb node3:sdb
Troubleshooting
After adding 3 (minimum required is 3) OSDs, their health should show HEALTH_OK when ceph health is executed in the nodes. For example:
> ssh node1 sudo ceph health
HEALTH_OK
However, in my case, I ran into a problem:
> ssh node1 sudo ceph health
HEALTH_ERR 64 pgs are stuck inactive for more than 300 seconds; 64 pgs stuck inactive; 64 pgs stuck unclean
Looking at the cluster status, I noticed 2 of the OSDs were down:
> ssh node1 sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.01469 root default
-2 0.00490 host node1
0 0.00490 osd.0 down 0 1.00000
-3 0.00490 host node2
1 0.00490 osd.1 up 1.00000 1.00000
-4 0.00490 host node3
2 0.00490 osd.2 down 0 1.00000
I have checked that sdb was automatically set up with xfs, so that’s not an issue.
> mount | grep sdb
/dev/sdb1 on /var/lib/ceph/osd/ceph-2 type xfs (rw,noatime,attr2,inode64,noquota)
I came across this thread, which mentions maybe there are some problems with the OSD processes. So following this page, I ran the following to check on the ceph processes in the down nodes (i.e. node1 and node3).
> sudo systemctl status ceph\*.service ceph\*.target
● ceph-mon.target - ceph target allowing to start/stop all ceph-mon@.service instances at
Loaded: loaded (/lib/systemd/system/ceph-mon.target; enabled; vendor preset: enabled)
Active: active since Thu 2017-08-17 22:18:13 UTC; 1h 25min ago
Aug 17 22:18:13 ceph-node3 systemd[1]: Reached target ceph target allowing to start/stop a
● ceph-radosgw.target - ceph target allowing to start/stop all ceph-radosgw@.service insta
Loaded: loaded (/lib/systemd/system/ceph-radosgw.target; enabled; vendor preset: enable
Active: active since Thu 2017-08-17 22:18:14 UTC; 1h 25min ago
Aug 17 22:18:14 ceph-node3 systemd[1]: Reached target ceph target allowing to start/stop a
● ceph-mds.target - ceph target allowing to start/stop all ceph-mds@.service instances at
Loaded: loaded (/lib/systemd/system/ceph-mds.target; enabled; vendor preset: enabled)
Active: active since Thu 2017-08-17 22:18:12 UTC; 1h 25min ago
Aug 17 22:18:12 ceph-node3 systemd[1]: Reached target ceph target allowing to start/stop a
● ceph.target - ceph target allowing to start/stop all ceph*@.service instances at once
Loaded: loaded (/lib/systemd/system/ceph.target; enabled; vendor preset: enabled)
Active: active since Thu 2017-08-17 22:18:11 UTC; 1h 25min ago
Aug 17 22:18:11 ceph-node3 systemd[1]: Reached target ceph target allowing to start/stop a
● ceph-osd.target - ceph target allowing to start/stop all ceph-osd@.service instances at
Loaded: loaded (/lib/systemd/system/ceph-osd.target; enabled; vendor preset: enabled)
Active: active since Thu 2017-08-17 22:18:13 UTC; 1h 25min ago
Aug 17 22:18:13 ceph-node3 systemd[1]: Reached target ceph target allowing to start/stop a
root@ceph-node3:/var/lib/ceph/osd/ceph-2# systemctl status ceph-osd.target
● ceph-osd.target - ceph target allowing to start/stop all ceph-osd@.service instances at
Loaded: loaded (/lib/systemd/system/ceph-osd.target; enabled; vendor preset: enabled)
Active: active since Thu 2017-08-17 22:18:13 UTC; 1h 25min ago
Aug 17 22:18:13 ceph-node3 systemd[1]: Reached target ceph target allowing to start/stop a
(sorry some output has been cut off)
Notice that there is no ceph-osd@{id}.service. So I tried restarting ceph-osd.target to see if the osd service can be restarted.
> systemctl restart ceph-osd.target
Inspecting the services again, now ceph-osd@2.service is visible but has an error:
> sudo systemctl status ceph\*.service ceph\*.target
...
● ceph-osd@2.service - Ceph object storage daemon
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; enabled; vendor preset: enabled)
Active: inactive (dead) (Result: exit-code) since Thu 2017-08-17 23:47:50 UTC; 25s ago
Process: 9187 ExecStart=/usr/bin/ceph-osd -f --cluster ${CLUSTER} --id %i --setuser ceph --setgroup ceph (code=exited, status=1/FAILURE)
Process: 9140 ExecStartPre=/usr/lib/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id %i (code=exited, status=0/SUCCESS)
Main PID: 9187 (code=exited, status=1/FAILURE)
Aug 17 23:47:44 ceph-node3 systemd[1]: ceph-osd@2.service: Main process exited, code=exited, status=1/FAILURE
Aug 17 23:47:44 ceph-node3 systemd[1]: ceph-osd@2.service: Unit entered failed state.
Aug 17 23:47:44 ceph-node3 systemd[1]: ceph-osd@2.service: Failed with result 'exit-code'.
Aug 17 23:47:50 ceph-node3 systemd[1]: Stopped Ceph object storage daemon.
...
I found the logs under /var/log/ceph/ceph-osd.2.log, which showed a permission problem:
> cat /var/log/ceph/ceph-osd.2.log
...
2017-08-17 22:40:26.280895 7f0a2064e8c0 -1 filestore(/var/lib/ceph/osd/ceph-2) mount failed to open journal /var/lib/ceph/osd/ceph-2/journal: (13) Permission denied
2017-08-17 22:40:26.281648 7f0a2064e8c0 -1 osd.2 0 OSD:init: unable to mount object store
2017-08-17 22:40:26.281659 7f0a2064e8c0 -1 ** ERROR: osd init failed: (13) Permission denied
...
/var/lib/ceph/osd/ceph-2/journal is mapped to a disk, which is in turned mapped to sdb2.
lrwxrwxrwx 1 ceph ceph 58 Aug 17 22:37 journal -> /dev/disk/by-partuuid/f01452f6-b9ba-41c8-b5d6-f8e0ebf30e18
lrwxrwxrwx 1 root root 10 Aug 17 22:38 f01452f6-b9ba-41c8-b5d6-f8e0ebf30e18 -> /dev/sdb2
It turns out that, for some reason, /dev/sdb2 did not have the correct permission:
> ls -lah /dev/sd*
brw-rw---- 1 root disk 8, 0 Aug 17 21:03 /dev/sda
brw-rw---- 1 root disk 8, 1 Aug 17 21:03 /dev/sda1
brw-rw---- 1 root disk 8, 16 Aug 17 22:37 /dev/sdb
brw-rw---- 1 ceph ceph 8, 17 Aug 17 22:37 /dev/sdb1
brw-rw---- 1 root root 8, 18 Aug 17 22:38 /dev/sdb2
I simply changed the owner:group back to ceph, and the OSD process did not complain anymore.
> chown ceph:ceph /dev/sdb2
> systemctl status ceph-osd@2.service
● ceph-osd@2.service - Ceph object storage daemon
Loaded: loaded (/lib/systemd/system/ceph-osd@.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2017-08-17 23:54:53 UTC; 41s ago
Process: 10527 ExecStartPre=/usr/lib/ceph/ceph-osd-prestart.sh --cluster ${CLUSTER} --id %i (code=exited, status=0/SUCCESS)
Main PID: 10573 (ceph-osd)
CGroup: /system.slice/system-ceph\x2dosd.slice/ceph-osd@2.service
└─10573 /usr/bin/ceph-osd -f --cluster ceph --id 2 --setuser ceph --setgroup ceph
Aug 17 23:54:53 ceph-node3 systemd[1]: ceph-osd@2.service: Service hold-off time over, scheduling restart.
Aug 17 23:54:53 ceph-node3 systemd[1]: Stopped Ceph object storage daemon.
Aug 17 23:54:53 ceph-node3 systemd[1]: Starting Ceph object storage daemon...
Aug 17 23:54:53 ceph-node3 ceph-osd-prestart.sh[10527]: create-or-move updated item name 'osd.2' weight 0.0049 at location {host=ceph-no
Aug 17 23:54:53 ceph-node3 systemd[1]: Started Ceph object storage daemon.
Aug 17 23:54:53 ceph-node3 ceph-osd[10573]: starting osd.2 at :/0 osd_data /var/lib/ceph/osd/ceph-2 /var/lib/ceph/osd/ceph-2/journal
Aug 17 23:54:53 ceph-node3 ceph-osd[10573]: 2017-08-17 23:54:53.776704 7f565e5aa8c0 -1 osd.2 0 log_to_monitors {default=true}
Fix the permission of /dev/sdb2 of all the failing nodes, and now the health of all 3 nodes are good: (running from admin node)
> ssh node3 sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.01469 root default
-2 0.00490 host node1
0 0.00490 osd.0 up 1.00000 1.00000
-3 0.00490 host node2
1 0.00490 osd.1 up 1.00000 1.00000
-4 0.00490 host node3
2 0.00490 osd.2 up 1.00000 1.00000
> ssh node2 sudo ceph health
HEALTH_OK